AMAX AI Factory亮相GTC26,携手NVIDIA共筑未来
2026.03.19

核心硬件
三代芯片架构齐发
黄仁勋在演讲中揭晓了三款重磅芯片架构,构建起"未来旗舰+量产主力+推理专用"的完整算力矩阵,彻底突破传统算力瓶颈。
其一,Vera Rubin下一代超级芯片平台,作为Blackwell架构的继任者,成为本次发布的核心亮点。
该平台集成了Vera CPU(88个定制核心)、Rubin GPU(配备288GB HBM4显存)NVIDIA NVLink 6 交换机、NVIDIA ConnectX-9 SuperNIC、NVIDIA BlueField-4 DPU、NVIDIA Spectrum-6 以太网交换机和NVIDIA Groq 3 LPU。这些芯片设计为协同运作,构成一台强大的 AI 超级计算机,可为 AI 的各个阶段提供动力——从大规模预训练、后训练、测试阶段扩展到实时智能体式推理。

其二,Feynman(费曼),作为继Vera Rubin之后的下一代平台架构,提前曝光原型。该架构搭载LP 40处理器和Rosa CPU,采用台积电1.6nm A16制程,是全球首款集成共封装光学(CPO)技术的AI芯片,核心突破在于将LPU(语言处理单元)与GPU深度集成,专门攻克推理延迟和内存墙问题。Feynman架构的带宽将提升10倍、传输能耗降低70%以上,推理性能为Blackwell架构的5倍,计划2028年启动生产,2029年向客户交付。
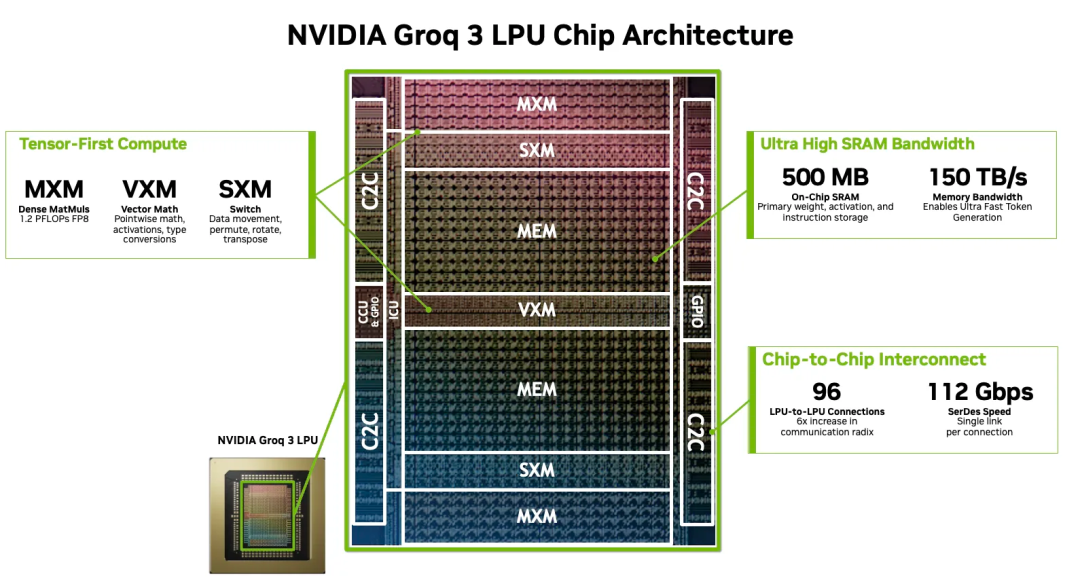
其三,Groq 3 LPU(语言处理单元),它专为AI代理的超低延迟推理设计,通过片上集成500MB SRAM,提供了高达150TB/s的内存带宽,远超传统HBM。在Vera Rubin平台中,LPU作为Rubin GPU的专用"解码协处理器",通过Dynamo软件协同,专门负责生成Token的解码阶段。这种分工使AI代理间通信吞吐量从每秒100 token飙升至1500 token以上,系统整体推理吞吐量/功耗比因此提升35倍,为实时多轮交互和复杂工具调用提供了澎湃动力
Token King
重塑数据中心形态
"过去大家讲'美猴王(Monkey King)',现在更值得争夺的是'Token 王(Token King)'。"
黄仁勋在演讲中提出,未来的数据中心不再只是堆放服务器的机房,而是生产智能的工厂;衡量这座工厂效率的关键,不只是算力有多强,而是能以多高效率、多少成本持续产出 Token。AI 工厂的竞争不再是单点芯片的比拼,而是整柜、整机架、整数据中心的系统级竞争:供电、冷却、网络、存储、算力调度、能耗效率共同决定最终的产出成本。
为实现 AI 工厂的规模化落地,NVIDIA 推出全栈基础设施解决方案,将数据中心升级为整柜交付的 AI 生产单元,通过标准化的计算、网络、存储、冷却和管理模块,实现 AI 部署的一致性与可扩展性。黄仁勋强调,NVIDIA 系统已成为全球"成本最低的基础设施",其通用性可覆盖超大型云服务商、主权云、企业、工业等多个领域,目前 60% 的业务来自全球前五的超大型云服务商,其余 40% 广泛分布于各行业场景。他同时上调算力需求预期,将 2027 年的算力需求预测由 5000 亿美元翻倍至 1 万亿美元,强调"每一座数据中心都受电力限制,每瓦 Token 吞吐量将决定企业生产成本与商业竞争力"。

AMAX
AI Factory Solution
AMAX 同步展示的AI Factory Solution,是基于NVIDIA官方架构打造、经过全链路验证的端到端生产级 AI 基础设施蓝图,也是 AMAX 本次参展的核心方案。该方案将 NVIDIA 参考设计,通过 AMAX 工程化落地为可直接交付、可快速量产的 AI 工厂,帮助企业实现"首日上线、稳定扩产"。

作为AI基础设施领域的重要参与者,AMAX Solution精准契合当下AI工业化浪潮中,行业对高效、节能、可扩展算力基础设施的核心需求,依托自身在液冷技术与AI工程化落地领域的深厚积累,与NVIDIA的全栈产品形成高效互补,深度协同赋能AI工厂规模化部署,共同推动AI从技术研发走向产业落地,加速AI工业化进程。
未来,AMAX将继续与NVIDIA及广大合作伙伴携手同行,深化技术创新与生态共建,聚焦医疗、生命科学、半导体设计、工业AI等关键行业场景,以标准化、模块化、可复制的基础设施方案,帮助全球企业降低AI部署成本、提升算力利用效率、挖掘AI商业价值,助力AI技术深度渗透各行各业,共筑AI工业化时代的全新生态格局。