千问崩溃背后的,算力拷问!
2026.02.10
近日,大家的朋友圈想必都被千问"30亿免单"新春活动刷屏了,可不少网友却遭遇收不到回复、刷不出订单的窘境。究其原因,是活动引发的流量暴增,让服务器直接承压崩溃,这一情况也成为全网热议的技术热点。据悉,该活动 9 小时订单便破千万,瞬时QPS从日常 1 万骤升至 80 万,直接突破系统 24 万的理论承载上限,随之而来的是活动页面卡顿、支付链路阻塞、数据传输延迟等一系列问题。
这场突如其来的"流量海啸",不仅暴露了活动方对用户增长规模的预判不足,更直指行业核心痛点:后端算力基建的弹性、稳定性与协同性,才是支撑高并发场景的底层核心。

从千问事件延伸至全行业,无论是电商大促、AI 应用落地,还是政企数字化服务,突发高并发已成为常态,而服务器端的性能及技术短板,往往是压垮系统的最关键所在。千问崩溃的背后,实则是高并发场景下对服务器端的五大核心技术与性能诉求,而这也正是所有企业数字化建设中必须攻克的算力课题。
诉求一:瞬时高并发的算力弹性支撑能力
千问事件中,裂变式传播带来的流量呈"量级式跨越",初始服务器资源池仅能支撑预估流量的 1/3,暴增的请求直接击穿算力承载上限。这要求服务器端必须具备超大规模算力储备 + 动态调度能力,既能应对日常低负载的资源高效利用,又能在流量突发时毫秒级扩容,实现算力资源的按需分配,从根本上解决"资源缺口"问题。
诉求二:多负载并行的异构算力协同能力
千问此次崩溃的另一大诱因,是 AI 购物指令处理(比价、支付、门店调度)与核心 AI 生成任务(问答、创作)的双重算力负载叠加。这对服务器的CPU+GPU/NPU异构算力协同提出严苛要求:需要高性能 CPU 提供充足的算力调度与数据喂入能力,搭配专业级 GPU 实现 AI 任务的高效处理,同时依托高带宽通道,消除 CPU 与 GPU、GPU 与 GPU 之间的数据传输瓶颈,确保多负载并行不卡顿。
诉求三:高负载下的算力持续稳定能力
当服务器长期处于 80 万 QPS 的超高负载状态,硬件发热、性能衰减成为必然问题。若散热方案不到位,CPU/GPU 将因高温触发降频,进一步降低算力输出,形成"负载越高 - 性能越差 - 系统越卡"的恶性循环。这要求服务器端必须配备高效散热解决方案,在高负载下实现硬件精准控温,保障算力持续稳定释放,无性能衰减。
诉求四:跨系统调度的高速数据存取能力
千问活动接入 30 万家线下门店,跨淘宝、饿了吗、盒马等多平台的调度,需要海量数据的高速读写与流转。而传统存储方案存在的空间利用率低、数据孤岛、读写延迟高等问题,会直接导致跨系统数据调度卡顿。这要求服务器端搭配高可用分布式存储系统,实现海量数据的低延迟存取、多协议共享,打破数据孤岛,支撑跨系统、高并发的数椐交互需求。
诉求五:全国化服务的低延迟算力输出能力
千问活动的用户遍布全国,而算力中心的地域布局,直接决定了用户端的响应延迟。若算力资源集中在单一区域,偏远地区用户的请求将因跨地域传输产生高延迟,进一步加剧系统拥堵。这要求企业进行算力的全国化多点布控,实现就近算力输出,确保全国范围内用户请求的低延迟响应,提升整体系统承载效率。

千问事件给全行业敲响警钟:流量红利的背后,是算力基建的硬实力较量。超集信息作为深耕 IT 基础设施领域 48 年的专业算力解决方案提供商,依托对算力场景的深度理解与技术沉淀,打造了从算力硬件、散热方案到存储系统、算力租赁的全栈解决方案,精准匹配高并发场景下的六大核心诉求,为企业应对流量海啸、实现业务稳定运行保驾护航。
超集信息双路高性能服务器ServMAX® C2424-H4,基于AMD EPYC 9005 系列处理器打造,最高支持 192 核 384 线程,Zen5 架构带来37% 的 AI/HPC 场景 IPC 提升,搭配 5GHz 高频配置,为高并发场景提供极致算力储备;集群化部署下,结合PlatforMax算力调度系统,可实现高效资源扩容,从硬件层面解决算力缺口问题。

超集信息智算服务器ServMAX® G448-H4,深度优化 CPU+GPU 异构算力协同架构,搭载 AMD EPYC 9005 系列处理器同时,支持 8 张专业级 GPU 并行部署,160条 PCIe 5.0 通道实现 CPU 与 GPU 之间的超高带宽数据传输,消除数据瓶颈;同时适配 NVIDIA、海光、昇腾等多款专业级 AI 加速卡,可根据业务需求灵活选型,完美支撑 AI 推理、业务处理等多负载并行运行,算力利用率稳定在 85% 以上。

针对高负载下的散热痛点,超集信息推出覆盖边缘端、工作站、服务器的全场景液冷解决方案,冷板式液冷设计让热交换效率较风冷提升 60%,30℃环温下满负载 CPU、GPU 温度较风冷降低20%以上,彻底杜绝高温降频问题;同时,液冷数据中心方案可将全年平均 PUE 降低至 1.1以下,在保障算力持续稳定释放的同时,实现能耗优化,降低高负载运行成本。

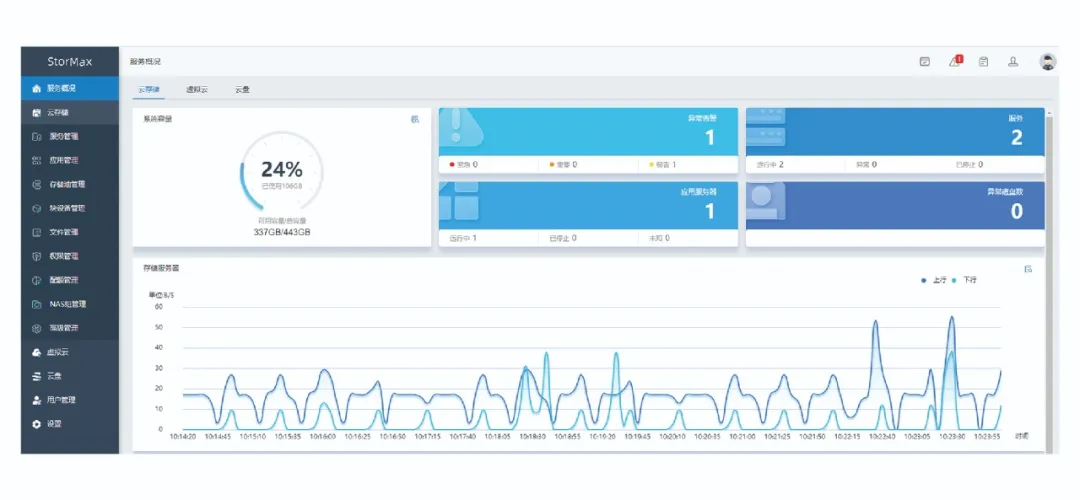
超集信息StorMax 分布式存储系统专为高并发数据交互设计,采用自研纠删码技术,将存储空间利用率提升至80%-95%,较传统三副本方案提升 140% 以上;同时支持文件、块、对象、大数据多协议共享,打造统一存储池,打破数据孤岛,实现海量数据的低延迟读写(读写延迟稳定在 1ms 以内),完美支撑跨系统、高并发的数椐调度需求,适配电商、AI 等场景的海量数据交互。
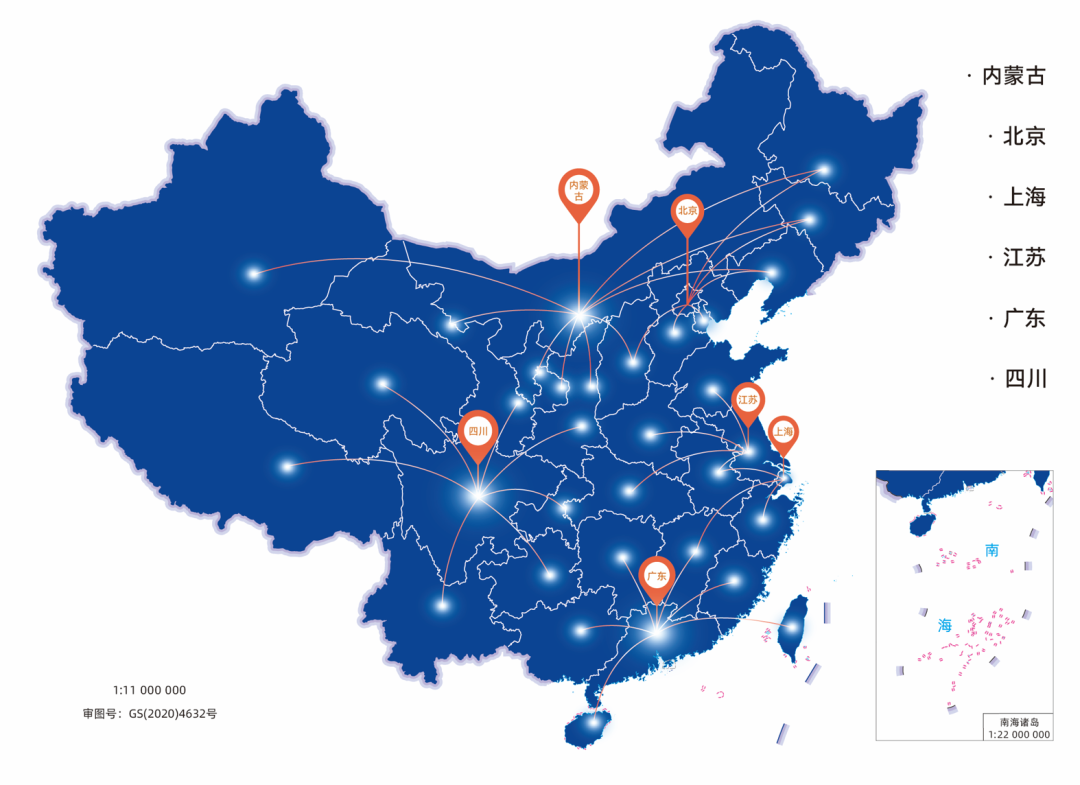
超集信息在北京、上海、江苏、广东、四川等全国核心区域布局算力中心,推出高性能算力租赁服务,涵盖裸金属、集群、云主机等多种计算资源,支持 GPU 数量、CPU 核数、存储容量的灵活选择,基本实现全国 30ms 内无感延迟算力输出;同时预置 TensorFlow、Pytorch 等主流 AI 框架,分钟级获取实例环境,企业无需高额硬件投入,即可按需获取算力资源,轻松应对大促、活动等突发高并发场景,实现算力成本的最优配置。
超集信息拥有专业的技术服务团队,提供 4 小时技术响应 + 8 小时方案呈现 + 7×24 小时驻场运维的全链路服务,从方案设计、部署实施到后期运维,为企业提供一站式技术支持;同时配备 SLM 动环监测平台,实时监控算力硬件、散热系统、存储设备的运行状态,实现故障提前预警与快速处理,确保算力系统全年稳定运行。

从千问的流量海啸,到电商大促、AI 应用落地、政企数字化服务的各类高并发场景,算力基建已成为企业数字化转型的核心竞争力。超集信息始终以技术创新为核心,以场景需求为导向,打造高弹性、高稳定、高性价比的全栈算力解决方案,为企业筑牢硬核算力底座,让企业在追逐流量红利的同时,无惧流量海啸,实现业务的持续稳定增长。
获取更多产品信息及专业技术支持,欢迎垂询"400-860-6560"。现在咨询,可获取专属"存储成本优化方案",免费评估旧设备利旧潜力!